AWS Machine Learning Blog
Category: Intermediate (200)

Mitigating risk: AWS backbone network traffic prediction using GraphStorm
In this post, we show how you can use our enterprise graph machine learning (GML) framework GraphStorm to solve prediction challenges on large-scale complex networks inspired by our practices of exploring GML to mitigate the AWS backbone network congestion risk.

Unlock cost-effective AI inference using Amazon Bedrock serverless capabilities with an Amazon SageMaker trained model
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. In this post, I’ll show you how to use Amazon Bedrock—with its fully managed, on-demand API—with your Amazon SageMaker trained or fine-tuned model.

Efficiently build and tune custom log anomaly detection models with Amazon SageMaker
In this post, we walk you through the process to build an automated mechanism using Amazon SageMaker to process your log data, run training iterations over it to obtain the best-performing anomaly detection model, and register it with the Amazon SageMaker Model Registry for your customers to use it.

Using transcription confidence scores to improve slot filling in Amazon Lex
When building voice-enabled chatbots with Amazon Lex, one of the biggest challenges is accurately capturing user speech input for slot values. Transcription confidence scores can help ensure reliable slot filling. This blog post outlines strategies like progressive confirmation, adaptive re-prompting, and branching logic to create more robust slot filling experiences.

How Twitch used agentic workflow with RAG on Amazon Bedrock to supercharge ad sales
In this post, we demonstrate how we innovated to build a Retrieval Augmented Generation (RAG) application with agentic workflow and a knowledge base on Amazon Bedrock. We implemented the RAG pipeline in a Slack chat-based assistant to empower the Amazon Twitch ads sales team to move quickly on new sales opportunities.

Speed up your cluster procurement time with Amazon SageMaker HyperPod training plans
In this post, we demonstrate how you can use Amazon SageMaker HyperPod training plans, to bring down your training cluster procurement wait time. We guide you through a step-by-step implementation on how you can use the (AWS CLI) or the AWS Management Console to find, review, and create optimal training plans for your specific compute and timeline needs. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.

Build generative AI applications quickly with Amazon Bedrock IDE in Amazon SageMaker Unified Studio
In this post, we’ll show how anyone in your company can use Amazon Bedrock IDE to quickly create a generative AI chat agent application that analyzes sales performance data. Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex data pipelines.

Scale ML workflows with Amazon SageMaker Studio and Amazon SageMaker HyperPod
The integration of Amazon SageMaker Studio and Amazon SageMaker HyperPod offers a streamlined solution that provides data scientists and ML engineers with a comprehensive environment that supports the entire ML lifecycle, from development to deployment at scale. In this post, we walk you through the process of scaling your ML workloads using SageMaker Studio and SageMaker HyperPod.

Fast and accurate zero-shot forecasting with Chronos-Bolt and AutoGluon
Chronos models are available for Amazon SageMaker customers through AutoGluon-TimeSeries and Amazon SageMaker JumpStart. In this post, we introduce Chronos-Bolt, our latest FM for forecasting that has been integrated into AutoGluon-TimeSeries.
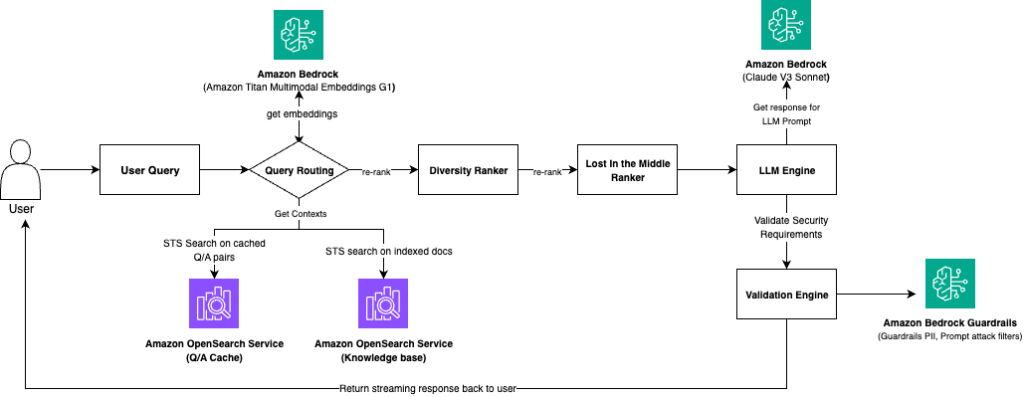
How Amazon Finance Automation built a generative AI Q&A chat assistant using Amazon Bedrock
Amazon Finance Automation developed a large language model (LLM)-based question-answer chat assistant on Amazon Bedrock. This solution empowers analysts to rapidly retrieve answers to customer queries, generating prompt responses within the same communication thread. As a result, it drastically reduces the time required to address customer queries. In this post, we share how Amazon Finance Automation built this generative AI Q&A chat assistant using Amazon Bedrock.