-
Software
- Procyon Benchmark Suite
- Benchmark de gerador de texto com IA
- Benchmark de criação de imagens de IA
- Benchmark de inferência de IA para Android
- Benchmark de visão computacional de IA
- Benchmark de duração da bateria
- Benchmark de consumo de bateria em uma hora
- Office Productivity Benchmark
- Photo Editing Benchmark
- Video Editing Benchmark
- Testdriver
- 3DMark
- 3DMark para Android
- 3DMark para iOS
- PCMark 10
- PCMark para Android
- VRMark
- MAIS...
-
Serviços
-
Suporte
-
Percepções
-
Compare
-
Mais
-


Procyon® AI Image Generation
Benchmark de desempenho de geração de imagens de IA de GPU
O benchmark de geração de imagens de IA Procyon fornece uma carga de trabalho consistente, precisa e compreensível para medir o desempenho de inferência de aceleradores de IA no dispositivo. Este benchmark foi desenvolvido em parceria com vários membros importantes da indústria para garantir que produza resultados justos e comparáveis em todos os hardwares suportados.
O benchmark inclui três testes para medir o desempenho desde NPUs de baixo consumo até placas gráficas independentes de última geração. O teste Stable Diffusion XL (FP16) é nossa carga de trabalho de inferência de IA mais exigente, e apenas as GPUs de última geração atendem aos requisitos mínimos para executá-lo. Para GPUs discretas moderadamente poderosas, recomendamos o teste Stable Diffusion (FP16) do 1.5. Finalmente, projetamos o teste Stable Diffusion 1.5 (INT8) para dispositivos de baixo consumo usando NPUs para cargas de trabalho de IA.
The Procyon AI Image Generation Benchmark can be configured to use a selection of different inference engines, and by default uses the recommended optimal inference engine for the system’s hardware.
Compre agoraRecursos
- Uma variedade de testes construída em torno de uma carga de trabalho de geração de imagens, usando redes neurais de última geração.
- Projetado para medir o desempenho de inferência de uma ampla gama de aceleradores de IA.
- Compare com NVIDIA® TensorRT™, Intel® OpenVINO™ e ONNX com DirectML.
- Verifique a implementação e a compatibilidade do mecanismo de inferência.
- Simple to set up and use via the Procyon application or via command-line.
- Teste com várias versões do modelo de IA Stable Diffusion.
- Compare até quatro resultados 4 lado a lado no aplicativo.
Detalhes do benchmark
Stable Diffusion, lançado em 2022, feita usando IA para geração de texto para imagem em hardware próprio, acessível ao consumidor comum. Dada a sua facilidade de acesso, amplo uso e aspecto criativo, a geração de texto para imagem rapidamente se tornou um dos casos de uso de IA mais memoráveis para o público.
O benchmark de geração de imagens de IA usa um conjunto de prompts de texto padronizados para uma carga de trabalho de geração de imagens de IA confiável e consistente. Os resultados fornecem uma pontuação geral para fácil comparação, bem como pontuações mais detalhadas e as imagens geradas para inspeções mais detalhadas de desempenho e qualidade.
| Teste | Carga de trabalho | Resolução da imagem | Tamanho do lote | Etapas |
|---|---|---|---|---|
| Stable Diffusion XL (FP16) | Pesado | 1024 x 1024 | 1 | 100 |
| Stable Diffusion 1.5 (FP16) | Médio | 512 x 512 | 4 | 100 |
| Stable Diffusion 1.5 (INT8) | Leve | 512 x 512 | 1 | 50 |
Resultados e insights
Pontuações de benchmark
Compare o desempenho da Inferência de IA com duas versões diferentes do modelo Stable Diffusion.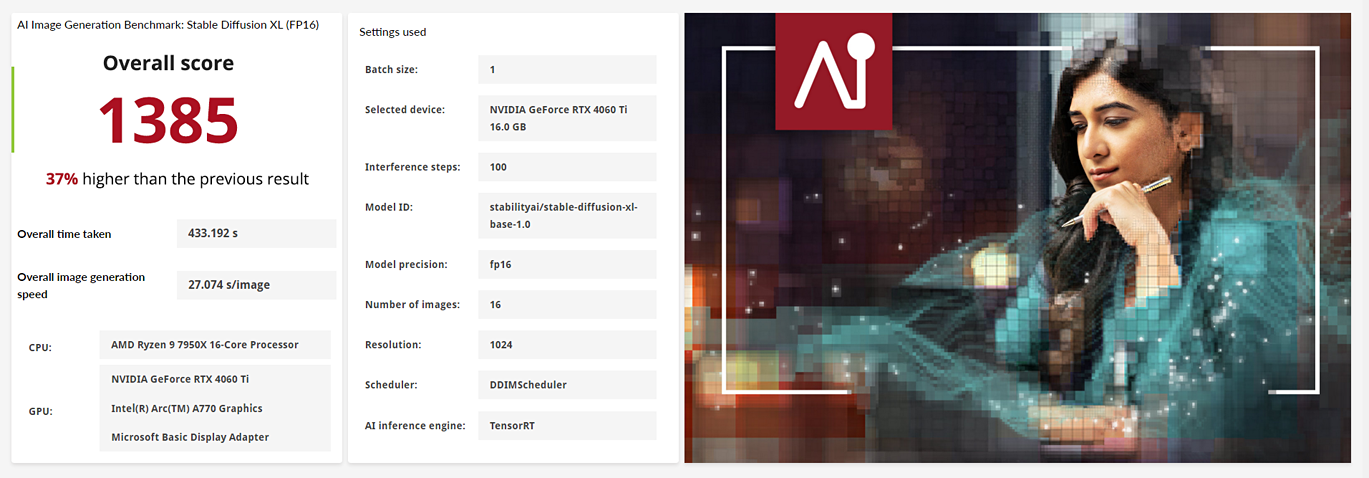
Pontuações detalhadas
Inspecione as imagens geradas e obtenha pontuações detalhadas para cada lote de geração de imagens.
Monitoramento de hardware
Obtenha métricas detalhadas sobre como as temperaturas de CPU e GPU, velocidades de clock e mudança de uso durante a execução do benchmark.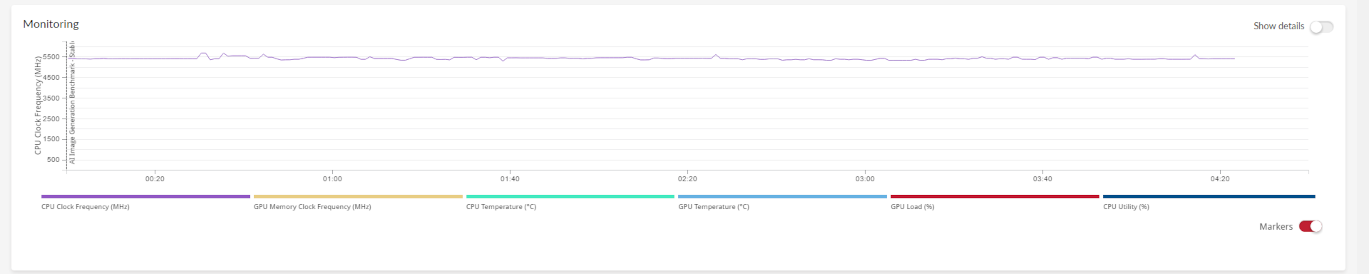
Desenvolvido com experiência no setor
Os benchmarks Procyon são projetados para uso industrial, empresarial e de imprensa com testes e recursos criados especificamente para usuários profissionais. The Procyon AI Image Generation Benchmark was designed and developed with industry partners through the UL Benchmark Development Program (BDP). O Benchmark Development Program é uma iniciativa da UL Solutions que visa criar benchmarks relevantes e imparciais, trabalhando em cooperação com os membros do programa.
Desempenho do mecanismo de inferência
With the Procyon AI Image Generation Benchmark, you can measure the performance of dedicated AI processing hardware and verify inference engine implementation quality with tests based on a heavy AI image generation workload.
Projetado por profissionais
Criamos nossos Benchmarks de inferência de IA Procyon para equipes de engenharia que precisam de ferramentas independentes e padronizadas para avaliar o desempenho geral de IA de implementações de mecanismos de inferência e hardware dedicado.
Rápido e fácil de usar
O benchmark é fácil de instalar e executar, nenhuma configuração complicada é necessária. Execute o benchmark usando o aplicativo Procyon ou por linha de comando. Visualize pontuações e gráficos de benchmark ou exporte arquivos de resultados detalhados para análise posterior.

Avaliação gratuita
Solicite avaliação gratuitaLicença da unidade
Solicite uma cotação Licença de imprensa- Annual site license for Procyon AI Image Generation Benchmark.
- Número ilimitado de usuários.
- Número ilimitado de dispositivos.
- Suporte prioritário por e-mail e telefone.
Programa de desenvolvimento de benchmark
Entre em contato conosco Saiba maisFale conosco
O Benchmark Development Program™ é uma iniciativa da UL Solutions para a construção de parcerias com empresas de tecnologia.
OEMs, ODMs, fabricantes de componentes e seus fornecedores estão convidados a se juntar a nós no desenvolvimento de novos benchmarks de processamento de IA. Entre em contato conosco para mais detalhes.
Requisitos mínimos do sistema
| Sistema Operacional | Windows 10, 64-bit ou Windows 11 |
|---|---|
| Processador | 2 GHz dual-core CPU |
| Memória | 16 GB |
| Armazenamento | 20 GB (75 GB recomendado) |
Requisitos do Stable Diffusion XL
| TensorRT | GPU RTX NVIDIA com 10 GB VRAM |
|---|---|
| OpenVINO | GPU Intel Arc independente com 16 GB VRAM |
| Tempo de execução do ONNX | 16 GB VRAM |
Requisitos do Stable Diffusion 1.5 (FP16)
| TensorRT | GPU RTX NVIDIA com 10 GB VRAM |
|---|---|
| OpenVINO | GPU Intel Arc independente com 8 GB VRAM ou sistema de GPU Intel integrada com 32 GB RAM |
| Tempo de execução do ONNX | 8 GB VRAM (GPU independente) - 32 GB RAM (GPU integrada) |
Requisitos do Stable Diffusion 1.5 (INT8)
| TensorRT | GPU NVIDIA série 30 ou posterior |
|---|---|
| OpenVINO | Uma NPU Intel, GPU integrada Intel ou GPU independente Intel Arc |
Suporte
Latest 1.1.157 | 9 de dezembro de 2024
Idiomas
- Inglês
- Alemão
- Japonês
- Português (Brasil)
- Chinês simplificado
- Espanhol