Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Peningkatan AI generatif untuk Apache Spark in Glue AWS
| Peningkatan AI generatif untuk pratinjau Apache Spark tersedia untuk AWS Glue di AWS Wilayah berikut: US East (Ohio), US East (Virginia N.), US West (Oregon), Asia Pasifik (Tokyo), dan Asia Pasifik (Sydney). Fitur pratinjau dapat berubah. |
Peningkatan Spark di AWS Glue memungkinkan insinyur dan pengembang data untuk meningkatkan dan memigrasikan pekerjaan AWS Glue Spark mereka yang ada ke rilis Spark terbaru menggunakan AI generatif. Insinyur data dapat menggunakannya untuk memindai pekerjaan AWS Glue Spark mereka, menghasilkan rencana peningkatan, menjalankan rencana, dan memvalidasi output. Ini mengurangi waktu dan biaya peningkatan Spark dengan mengotomatiskan pekerjaan yang tidak dibedakan untuk mengidentifikasi dan memperbarui skrip, konfigurasi, dependensi, metode, dan fitur Spark.

Cara kerjanya
Saat Anda menggunakan analisis pemutakhiran, AWS Glue mengidentifikasi perbedaan antara versi dan konfigurasi dalam kode pekerjaan Anda untuk menghasilkan rencana peningkatan. Paket pemutakhiran merinci semua perubahan kode, dan langkah-langkah migrasi yang diperlukan. Selanjutnya, AWS Glue membangun dan menjalankan aplikasi yang ditingkatkan di lingkungan kotak pasir untuk memvalidasi perubahan dan menghasilkan daftar perubahan kode bagi Anda untuk memigrasikan pekerjaan Anda. Anda dapat melihat skrip yang diperbarui bersama dengan ringkasan yang merinci perubahan yang diusulkan. Setelah menjalankan tes Anda sendiri, terima perubahan dan pekerjaan AWS Glue akan diperbarui secara otomatis ke versi terbaru dengan skrip baru.
Proses analisis peningkatan dapat memakan waktu untuk diselesaikan, tergantung pada kompleksitas pekerjaan dan beban kerja. Hasil analisis peningkatan akan disimpan di jalur Amazon S3 yang ditentukan, yang dapat ditinjau untuk memahami peningkatan dan potensi masalah kompatibilitas. Setelah meninjau hasil analisis peningkatan, Anda dapat memutuskan apakah akan melanjutkan dengan peningkatan aktual atau membuat perubahan yang diperlukan pada pekerjaan sebelum meningkatkan.
Prasyarat
Prasyarat berikut diperlukan untuk menggunakan AI generatif untuk meningkatkan pekerjaan di Glue: AWS
-
AWS PySpark Pekerjaan Glue 2 — hanya pekerjaan AWS Glue 2 yang dapat ditingkatkan ke AWS Glue 4.
-
IAMizin diperlukan untuk memulai analisis, meninjau hasil dan meningkatkan pekerjaan Anda. Untuk informasi lebih lanjut, lihat contoh di Izin bagian di bawah ini.
-
Jika menggunakan AWS KMS untuk mengenkripsi artefak analisis atau layanan untuk mengenkripsi data yang digunakan untuk analisis, maka AWS KMS izin tambahan diperlukan. Untuk informasi lebih lanjut, lihat contoh di AWS KMS kebijakan bagian di bawah ini.
Izin
-
Perbarui IAM kebijakan penelepon dengan izin berikut:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:StartJobUpgradeAnalysis", "glue:StartJobRun", "glue:GetJobRun", "glue:GetJob", "glue:BatchStopJobRun" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] }, { "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "<s3 script location associated with the job>" ] }, { "Effect": "Allow", "Action": ["s3:PutObject"], "Resource": [ "<result s3 path provided on API>" ] }, { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed in the API>" } ] }catatan
Jika Anda menggunakan dua AWS KMS kunci yang berbeda, satu untuk enkripsi artefak hasil dan lainnya untuk enkripsi metadata layanan, maka kebijakan tersebut perlu menyertakan kebijakan serupa untuk kedua kunci.
-
Perbarui peran Eksekusi dari pekerjaan yang Anda upgrade untuk menyertakan kebijakan in-line berikut:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }Misalnya, jika Anda menggunakan jalur Amazon S3
s3://amzn-s3-demo-bucket/upgraded-result, maka kebijakannya adalah:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:GetJobUpgradeAnalysis"], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] } ] }
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:StopJobUpgradeAnalysis", "glue:BatchStopJobRun" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] } ] }
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:ListJobUpgradeAnalyses"], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] } ] }
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:UpdateJob", "glue:UpgradeJob" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] }, { "Effect": "Allow", "Action": ["iam:PassRole"], "Resource": [ "<Role arn associated with the job>" ] } ] }
AWS KMS kebijakan
Untuk meneruskan AWS KMS kunci kustom Anda sendiri saat memulai analisis, silakan lihat bagian berikut untuk mengonfigurasi izin yang sesuai pada AWS KMS tombol.
Anda memerlukan izin (enkripsi/dekripsi) untuk meneruskan kunci. Dalam contoh kebijakan di bawah ini, AWS akun atau peran yang ditentukan oleh diizinkan untuk melakukan tindakan yang diizinkan: <IAM Customer caller ARN>
-
KMS: Decrypt memungkinkan dekripsi menggunakan kunci yang ditentukan. AWS KMS
-
kms: GenerateDataKey memungkinkan menghasilkan kunci data menggunakan kunci yang ditentukan AWS KMS .
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Anda perlu memberikan izin kepada AWS Glue untuk menggunakan AWS KMS kunci untuk enkripsi dan dekripsi kunci.
{ "Effect": "Allow", "Principal":{ "Service": "glue.amazonaws.com" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn>", "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:glue:<region>:<aws_account_id>:job/job-name" } } }
Kebijakan ini memastikan bahwa Anda memiliki izin enkripsi dan dekripsi pada kunci. AWS KMS
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Menjalankan analisis upgrade dan menerapkan skrip upgrade
Anda dapat menjalankan analisis peningkatan, yang akan menghasilkan rencana peningkatan pada pekerjaan yang Anda pilih dari tampilan Pekerjaan.
-
Dari Jobs, pilih job AWS Glue 2.0, lalu pilih Run upgrade analysis dari menu Actions.
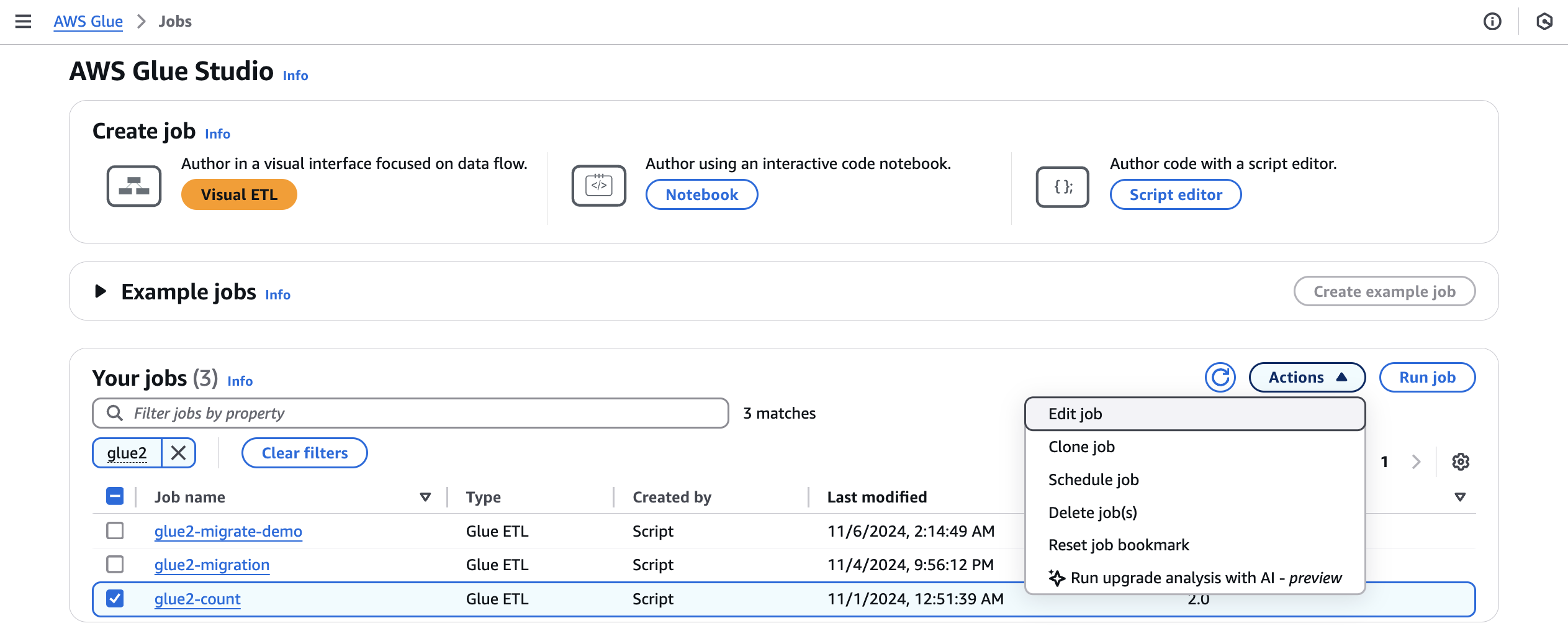
-
Di modal, pilih jalur untuk menyimpan paket peningkatan yang Anda hasilkan di jalur Hasil. Ini harus berupa bucket Amazon S3 yang dapat Anda akses dan tulis.
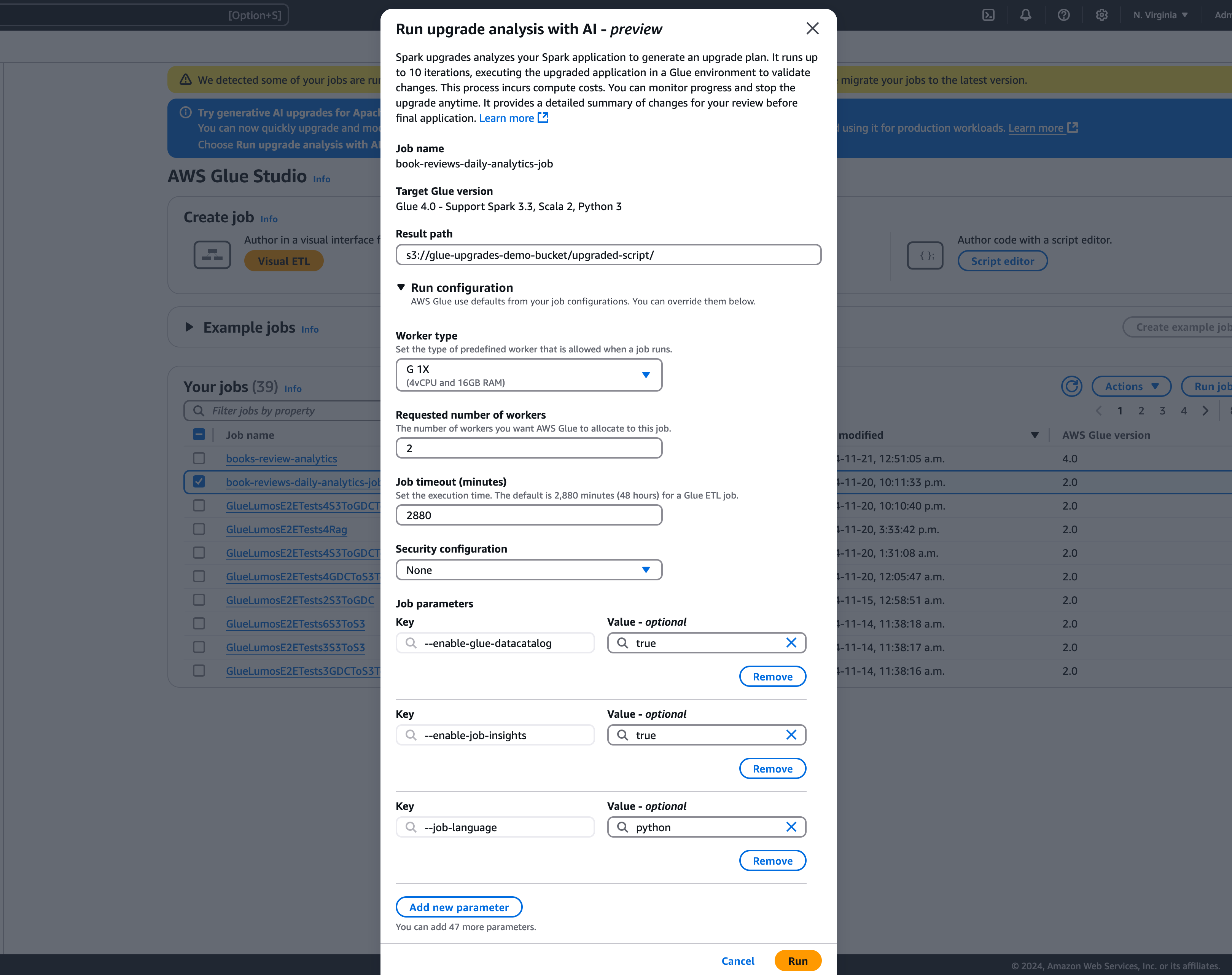
-
Konfigurasikan opsi tambahan, jika diperlukan:
-
Jalankan konfigurasi — opsional: Konfigurasi run adalah pengaturan opsional yang memungkinkan Anda menyesuaikan berbagai aspek proses validasi yang dilakukan selama analisis peningkatan. Konfigurasi ini digunakan untuk menjalankan skrip yang ditingkatkan dan memungkinkan Anda memilih properti lingkungan komputasi (tipe pekerja, jumlah pekerja, dll). Perhatikan bahwa Anda harus menggunakan akun pengembang non-produksi untuk menjalankan validasi pada kumpulan data sampel sebelum meninjau, menerima perubahan, dan menerapkannya ke lingkungan produksi. Konfigurasi run mencakup parameter yang dapat disesuaikan berikut:
-
Jenis pekerja: Anda dapat menentukan jenis pekerja yang akan digunakan untuk menjalankan validasi, memungkinkan Anda memilih sumber daya komputasi yang sesuai berdasarkan kebutuhan Anda.
-
Jumlah pekerja: Anda dapat menentukan jumlah pekerja yang akan disediakan untuk menjalankan validasi, memungkinkan Anda untuk menskalakan sumber daya sesuai dengan kebutuhan beban kerja Anda.
-
Job timeout (dalam hitungan menit): Parameter ini memungkinkan Anda untuk menetapkan batas waktu untuk validasi berjalan, memastikan bahwa pekerjaan berakhir setelah durasi tertentu untuk mencegah konsumsi sumber daya yang berlebihan.
-
Konfigurasi keamanan: Anda dapat mengonfigurasi pengaturan keamanan, seperti enkripsi dan kontrol akses, untuk memastikan perlindungan data dan sumber daya Anda selama validasi berjalan.
-
Parameter pekerjaan tambahan: Jika diperlukan, Anda dapat menambahkan parameter pekerjaan baru untuk lebih menyesuaikan lingkungan eksekusi untuk validasi berjalan.
Dengan memanfaatkan konfigurasi run, Anda dapat menyesuaikan proses validasi agar sesuai dengan kebutuhan spesifik Anda. Misalnya, Anda dapat mengonfigurasi proses validasi untuk menggunakan kumpulan data yang lebih kecil, yang memungkinkan analisis selesai lebih cepat dan mengoptimalkan biaya. Pendekatan ini memastikan bahwa analisis peningkatan dilakukan secara efisien sambil meminimalkan pemanfaatan sumber daya dan biaya terkait selama fase validasi.
-
-
Konfigurasi enkripsi - opsional:
-
Aktifkan enkripsi artefak upgrade: Aktifkan enkripsi saat istirahat saat menulis data ke jalur hasil. Jika Anda tidak ingin mengenkripsi artefak upgrade Anda, biarkan opsi ini tidak dicentang.
-
Kustomisasi enkripsi metadata layanan: Metadata layanan Anda dienkripsi secara default menggunakan kunci yang dimiliki. AWS Pilih opsi ini jika Anda ingin menggunakan kunci Anda sendiri untuk enkripsi.
-
-
-
Pilih Jalankan untuk memulai analisis peningkatan. Saat analisis sedang berjalan, Anda dapat melihat hasilnya di tab Analisis upgrade. Jendela detail analisis akan menampilkan informasi tentang analisis serta tautan ke artefak peningkatan.
-
Jalur hasil - di sinilah ringkasan hasil dan skrip peningkatan disimpan.
-
Skrip yang ditingkatkan di Amazon S3 - lokasi skrip peningkatan di Amazon S3. Anda dapat melihat skrip sebelum menerapkan upgrade.
-
Ringkasan upgrade di Amazon S3 — lokasi ringkasan upgrade di Amazon S3. Anda dapat melihat ringkasan pemutakhiran sebelum menerapkan peningkatan.
-
-
Ketika analisis pemutakhiran berhasil diselesaikan, Anda dapat menerapkan skrip pemutakhiran untuk meningkatkan pekerjaan Anda secara otomatis dengan memilih Terapkan skrip yang ditingkatkan.
Setelah diterapkan, versi AWS Glue akan diperbarui ke 4.0. Anda dapat melihat skrip baru di tab Script.
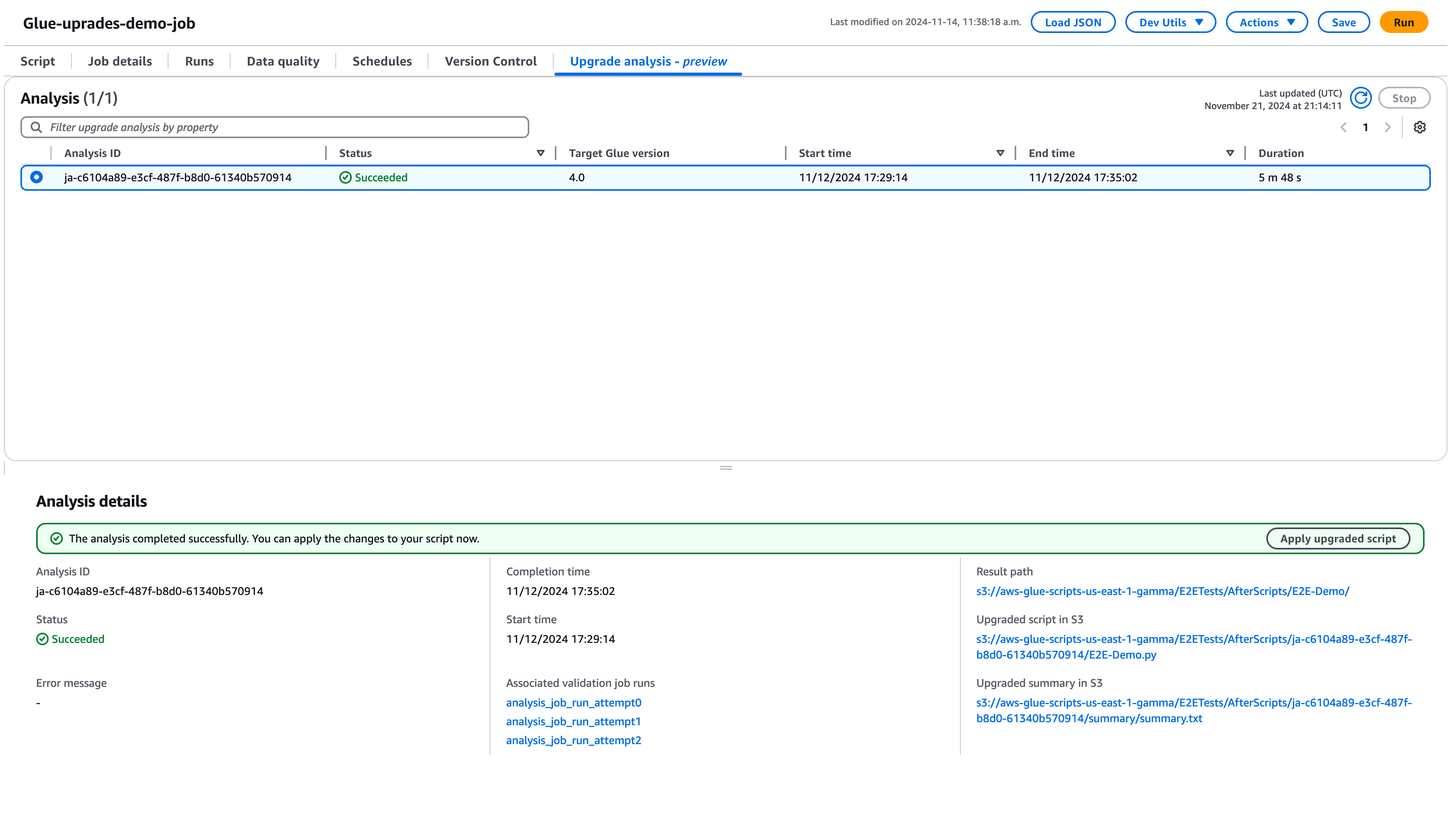
Memahami ringkasan pemutakhiran Anda
Contoh ini menunjukkan proses upgrade pekerjaan AWS Glue dari versi 2.0 ke versi 4.0. Pekerjaan sampel membaca data produk dari bucket Amazon S3, menerapkan beberapa transformasi ke data menggunakan SparkSQL, dan kemudian menyimpan hasil yang diubah kembali ke bucket Amazon S3.
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

Berdasarkan ringkasan, ada empat perubahan yang diusulkan oleh AWS Glue agar berhasil meningkatkan skrip dari AWS Glue 2.0 ke AWS Glue 4.0:
-
SQLKonfigurasi percikan (spark.sql.adaptive.enabled): Perubahan ini untuk mengembalikan perilaku aplikasi sebagai fitur baru untuk eksekusi kueri adaptif Spark diperkenalkan mulai Spark SQL 3.2. Anda dapat memeriksa perubahan konfigurasi ini dan selanjutnya dapat mengaktifkan atau menonaktifkannya sesuai preferensi mereka.
-
DataFrame APIchange: Opsi jalur tidak dapat hidup berdampingan dengan DataFrameReader operasi lain seperti
load(). Untuk mempertahankan perilaku sebelumnya, AWS Glue memperbarui skrip untuk menambahkan SQL konfigurasi baru (spark.sql.legacy. pathOptionBehavior.diaktifkan). -
SQLAPIPerubahan percikan: Perilaku
strfmtinformat_string(strfmt, obj, ...)telah diperbarui untuk melarang0$sebagai argumen pertama. Untuk memastikan kompatibilitas, AWS Glue telah memodifikasi skrip untuk digunakan1$sebagai argumen pertama. -
SQLAPIPerubahan percikan:
unbase64Fungsi ini tidak mengizinkan input string yang salah bentuk. Untuk mempertahankan perilaku sebelumnya, AWS Glue memperbarui skrip untuk menggunakantry_to_binaryfungsi.
Menghentikan analisis peningkatan yang sedang berlangsung
Anda dapat membatalkan analisis peningkatan yang sedang berlangsung atau hanya menghentikan analisis.
-
Pilih tab Analisis Peningkatan.
-
Pilih pekerjaan yang sedang berjalan, lalu pilih Stop. Ini akan menghentikan analisis. Anda kemudian dapat menjalankan analisis peningkatan lain pada pekerjaan yang sama.

Pertimbangan
Saat Anda mulai menggunakan Peningkatan Spark selama periode pratinjau, ada beberapa aspek penting yang perlu dipertimbangkan untuk penggunaan layanan yang optimal.
-
Lingkup dan Batasan Layanan: Rilis pratinjau berfokus pada peningkatan PySpark kode dari AWS Glue versi 2.0 ke versi 4.0. Pada saat ini, layanan menangani PySpark kode yang tidak bergantung pada dependensi pustaka tambahan. Anda dapat menjalankan peningkatan otomatis hingga 10 pekerjaan secara bersamaan di AWS akun, memungkinkan Anda meningkatkan beberapa pekerjaan secara efisien sambil menjaga stabilitas sistem.
-
Hanya PySpark pekerjaan yang didukung.
-
Analisis peningkatan akan habis waktu setelah 24 jam.
-
Hanya satu analisis peningkatan aktif yang dapat dijalankan pada satu waktu untuk satu pekerjaan. Pada tingkat akun, hingga 10 analisis peningkatan aktif dapat dijalankan secara bersamaan.
-
-
Mengoptimalkan Biaya Selama Proses Peningkatan: Karena Peningkatan Spark menggunakan AI generatif untuk memvalidasi paket peningkatan melalui beberapa iterasi, dengan setiap iterasi berjalan sebagai pekerjaan AWS Glue di akun Anda, penting untuk mengoptimalkan konfigurasi menjalankan pekerjaan validasi untuk efisiensi biaya. Untuk mencapai hal ini, sebaiknya tentukan Konfigurasi Jalankan saat memulai Analisis Peningkatan sebagai berikut:
-
Gunakan akun pengembang non-produksi dan pilih contoh kumpulan data tiruan yang mewakili data produksi Anda tetapi ukurannya lebih kecil untuk validasi dengan Peningkatan Spark.
-
Menggunakan sumber daya komputasi berukuran tepat, seperti pekerja G.1X, dan memilih jumlah pekerja yang sesuai untuk memproses data sampel Anda.
-
Mengaktifkan auto-scaling pekerjaan AWS Glue bila berlaku untuk menyesuaikan sumber daya secara otomatis berdasarkan beban kerja.
Misalnya, jika pekerjaan produksi Anda memproses terabyte data dengan 20 pekerja G.2X, Anda dapat mengonfigurasi pekerjaan pemutakhiran untuk memproses beberapa gigabyte data representatif dengan 2 pekerja G.2X dan auto-scaling diaktifkan untuk validasi.
-
-
Praktik Terbaik Pratinjau: Selama periode pratinjau, kami sangat menyarankan untuk memulai perjalanan peningkatan Anda dengan pekerjaan non-produksi. Pendekatan ini memungkinkan Anda untuk membiasakan diri dengan alur kerja peningkatan, dan memahami bagaimana layanan menangani berbagai jenis pola kode Spark.
-
Alarm dan pemberitahuan: Saat menggunakan fitur peningkatan AI Generatif pada suatu pekerjaan, pastikan alarm/pemberitahuan untuk pekerjaan yang gagal dinonaktifkan. Selama proses upgrade, mungkin ada hingga 10 pekerjaan gagal berjalan di akun Anda sebelum artefak yang ditingkatkan disediakan.
-
Aturan deteksi anomali: Matikan aturan deteksi anomali pada Job yang sedang ditingkatkan juga, karena data yang ditulis ke folder keluaran selama pekerjaan perantara berjalan mungkin tidak dalam format yang diharapkan saat validasi pemutakhiran sedang berlangsung.
Inferensi lintas wilayah dalam Peningkatan Spark
Peningkatan Spark didukung oleh Amazon Bedrock dan memanfaatkan inferensi lintas wilayah (). CRIS DenganCRIS, Spark Upgrades akan secara otomatis memilih wilayah optimal dalam geografi Anda (seperti yang dijelaskan secara lebih rinci di sini) untuk memproses permintaan inferensi Anda, memaksimalkan sumber daya komputasi yang tersedia dan ketersediaan model, dan memberikan pengalaman pelanggan terbaik. Tidak ada biaya tambahan untuk menggunakan inferensi lintas wilayah.
Permintaan inferensi lintas wilayah disimpan dalam AWS Wilayah yang merupakan bagian dari geografi tempat data awalnya berada. Misalnya, permintaan yang dibuat di AS disimpan di dalam AWS Wilayah di AS. Meskipun data tetap disimpan hanya di wilayah primer, saat menggunakan inferensi lintas wilayah, permintaan input dan hasil keluaran Anda dapat bergerak di luar wilayah utama Anda. Semua data akan dikirimkan dienkripsi melalui jaringan aman Amazon.
