As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Throughput alto para filas FIFO no Amazon SQS
As filas FIFO de throughput alto no Amazon SQS gerenciam com eficiência o throughput alto de mensagens enquanto mantêm uma ordem rígida de mensagens, garantindo confiabilidade e escalabilidade para aplicações que processam várias mensagens. Essa solução é ideal para cenários que exigem throughput alto e entrega ordenada de mensagens.
As filas FIFO de throughput alto do Amazon SQS não são necessárias em cenários em que a ordenação estrita de mensagens não é crucial e em que o volume de mensagens recebidas é relativamente baixo ou esporádico. Por exemplo, se você tiver uma aplicação de pequena escala que processa mensagens pouco frequentes ou não sequenciais, a complexidade e o custo adicionais associados às filas FIFO de throughput alto podem não ser justificados. Além disso, se a aplicação não exigir os recursos aprimorados de throughput fornecidos pelas filas FIFO de throughput alto, optar por uma fila padrão do Amazon SQS pode ser mais econômico e mais simples de gerenciar.
Para aumentar a capacidade de solicitação em filas FIFO de throughput alto, é recomendável aumentar o número de grupos de mensagens. Para ter mais informações sobre cotas de mensagens de throughput alto, consulte Amazon SQS service quotas no Referência geral da Amazon Web Services.
Consulte informações sobre cotas por fila e estratégias de distribuição de dados em Cotas de mensagens do Amazon SQS e Partições e distribuição de dados para alta taxa de transferência para filas FIFO do SQS.
Casos de uso de throughput alto para filas FIFO do Amazon SQS
Os seguintes casos de uso destacam as diversas aplicações de filas FIFO de throughput alto, mostrando sua eficácia em todos os setores e cenários:
-
Processamento de dados em tempo real: aplicações que lidam com fluxos de dados em tempo real, como processamento de eventos ou ingestão de dados de telemetria, podem se beneficiar de filas FIFO de throughput alto para lidar com o fluxo contínuo de mensagens, preservando sua ordem para uma análise precisa.
-
Processamento de pedidos de comércio eletrônico: em plataformas de comércio eletrônico em que manter a ordem das transações do cliente é fundamental, as filas FIFO de throughput alto garantem que os pedidos sejam processados sequencialmente e sem atrasos, mesmo durante os períodos de pico de compras.
-
Serviços financeiros: instituições financeiras que lidam com dados comerciais ou transacionais de alta frequência dependem de filas FIFO de throughput alto para processar dados e transações de mercado com latência mínima, ao mesmo tempo que cumprem os rígidos requisitos regulatórios para ordenação de mensagens.
-
Streaming de mídia: plataformas de streaming e serviços de distribuição de mídia utilizam filas FIFO de throughput alto para gerenciar a entrega de arquivos de mídia e conteúdo de streaming, garantindo experiências de reprodução suaves para os usuários e mantendo a ordem correta de entrega do conteúdo.
Partições e distribuição de dados para alta taxa de transferência para filas FIFO do SQS
O Amazon SQS armazena dados da fila FIFO em partições. Uma partição é uma alocação de armazenamento para uma fila que é automaticamente replicada em várias zonas de disponibilidade dentro de uma região da AWS. Você não gerencia partições. Em vez disso, o Amazon SQS lida com o gerenciamento de partições
Para filas FIFO, o Amazon SQS modifica o número de partições em uma fila nas seguintes situações:
-
Se a taxa de solicitação atual se aproximar ou exceder o que as partições existentes podem suportar, partições adicionais serão alocadas até que a fila atinja a cota regional. Para obter informações sobre cotas, consulte Cotas de mensagens do Amazon SQS.
-
Se as partições atuais tiverem baixa utilização, o número de partições poderá ser reduzido.
O gerenciamento de partições ocorre automaticamente em segundo plano e é transparente para as aplicações. Sua fila e mensagens estão disponíveis em todos os momentos.
Distribuindo dados por IDs de grupo de mensagens
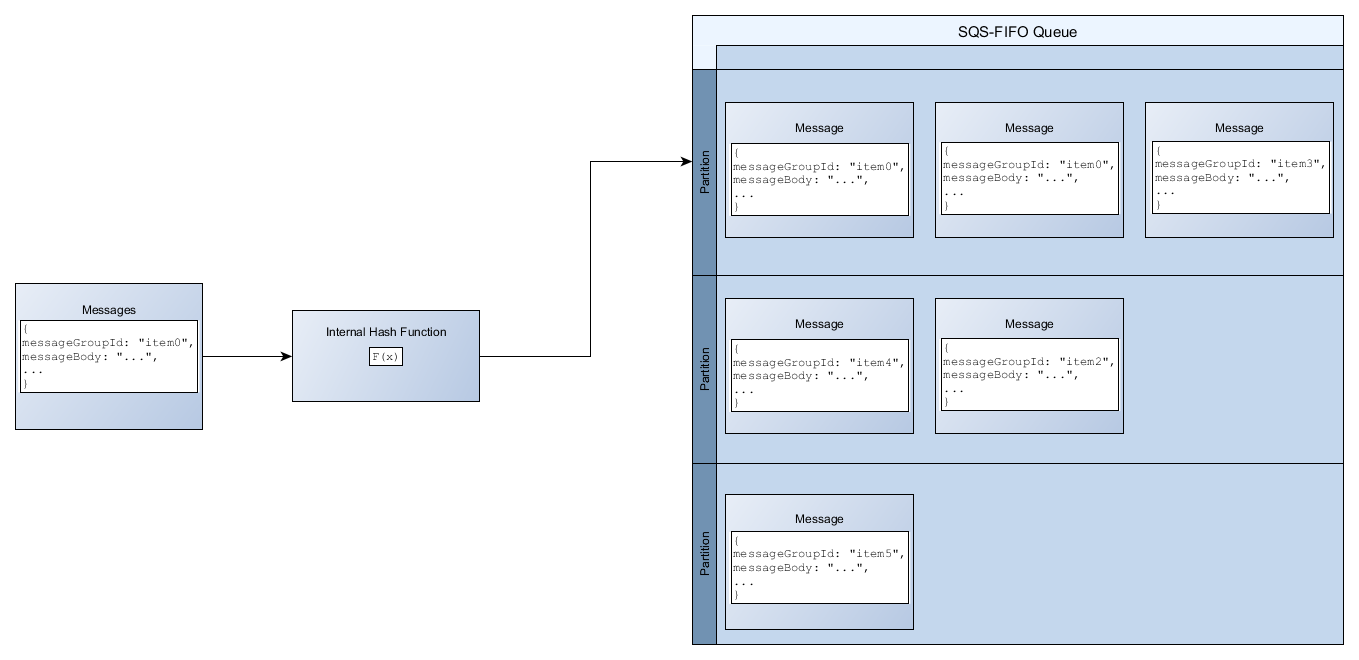
Para adicionar uma mensagem a uma fila FIFO, o Amazon SQS usa o valor do ID do grupo de mensagens de cada mensagem como entrada para uma função de hash interna. O valor de saída da função de hash determina a partição na qual a mensagem será armazenada.
O diagrama a seguir mostra uma fila que abrange várias partições. O ID do grupo de mensagens da fila é baseado no número do item. O Amazon SQS usa sua função de hash para determinar onde armazenar um novo item, neste caso, com base no valor de hash da string item0. Observe que os itens são armazenados na mesma ordem em que são adicionados à fila. A localização de cada item é determinada pelo valor de hash de seu ID de grupo de mensagens.
nota
O Amazon SQS é otimizado para distribuição uniforme de itens entre partições de uma fila FIFO, independentemente do número de partições. A AWS recomenda que você use IDs de grupo de mensagens que possam ter uma grande quantidade de valores distintos.
Otimizando a utilização de partições
Cada partição suporta até 3.000 mensagens por segundo com processamento em lote ou até 300 mensagens por segundo para operações de envio, recebimento e exclusão em regiões compatíveis. Para ter mais informações sobre cotas de mensagens de throughput alto, consulte Amazon SQS service quotas no Referência geral da Amazon Web Services.
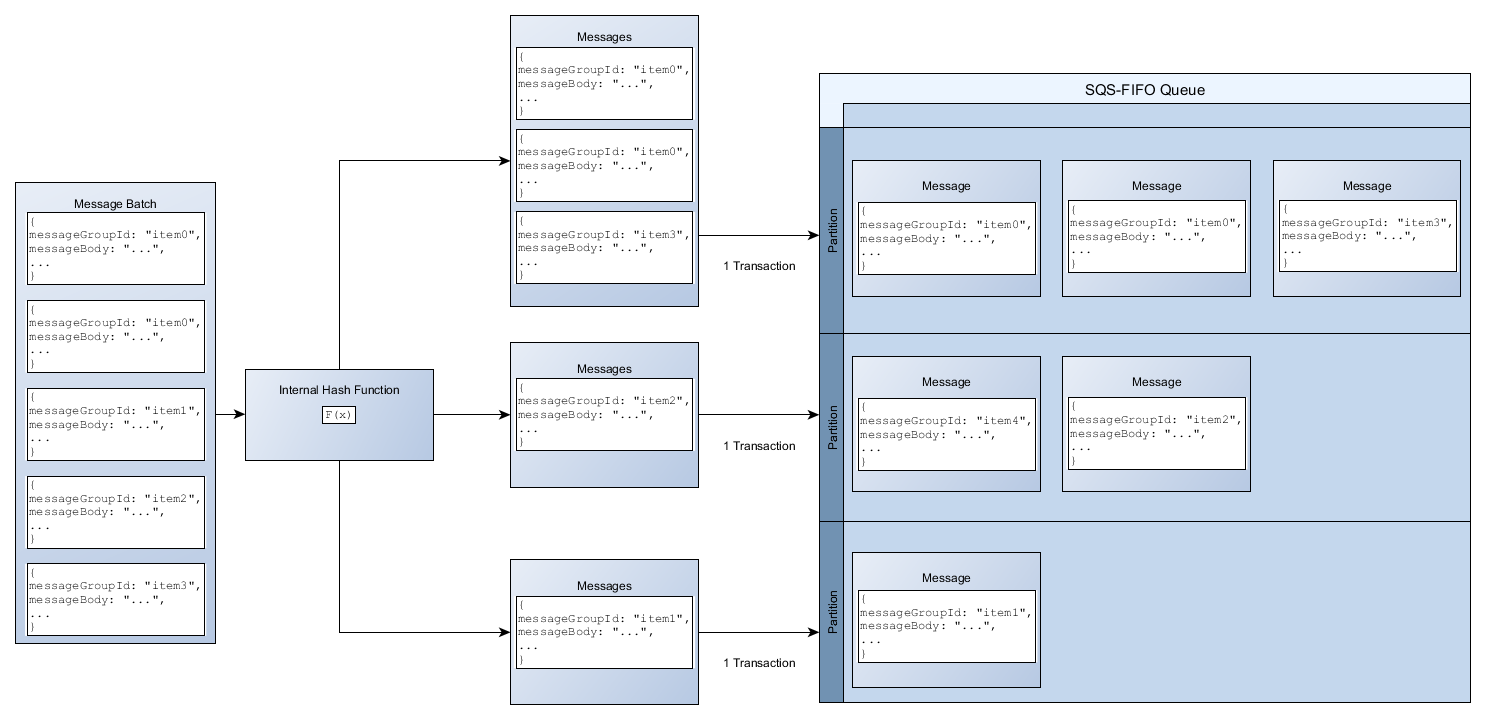
Ao usar APIs em lote, cada mensagem é encaminhada com base no processo descrito em Distribuindo dados por IDs de grupo de mensagens. Mensagens encaminhadas para a mesma partição são agrupadas e processadas em uma única transação.
Para otimizar a utilização de partições para a API da SendMessageBatch, a AWS recomenda o processamento em lotes de mensagens com os mesmos IDs de grupo de mensagens, sempre que possível.
Para otimizar a utilização da partição para as APIs DeleteMessageBatch e ChangeMessageVisibilityBatchAPIs, a AWS recomenda o uso de solicitações ReceiveMessage com o parâmetro MaxNumberOfMessages definido como 10 e agrupando os identificadores de recebimento retornados por uma única solicitação ReceiveMessage.
No exemplo a seguir, um lote de mensagens com vários IDs de grupo de mensagens é enviado. O lote é dividido em três grupos, com cada um contando para a cota da partição.
nota
O Amazon SQS garante somente que mensagens com a mesma função de hash interna do ID de grupo de mensagens sejam agrupadas em uma solicitação em lote. Dependendo da saída da função hash interna e do número de partições, mensagens com diferentes IDs de grupo de mensagens podem ser agrupadas. Como a função hash ou o número de partições pode ser alterado a qualquer momento, as mensagens agrupadas em um ponto podem não ser agrupadas posteriormente.
