satisfaction_level last_evaluation number_project average_montly_hours time_spend_company Work_accident left
0 0.38 0.53 2 157 3 0 1
1 0.80 0.86 5 262 6 0 1
2 0.11 0.88 7 272 4 0 1
3 0.72 0.87 5 223 5 0 1
4 0.37 0.52 2 159 3 0 1
使用逻辑回归完成员工离职预测
该数据集来源于Kaggle竞赛平台,共计14999条样本和10个特征,本案例希望通过分析现有的员工离职数据,建立模型预测有可能离职的员
工。
内容概要
1 数据概览
2 数据预处理
3 数据探索及可视化
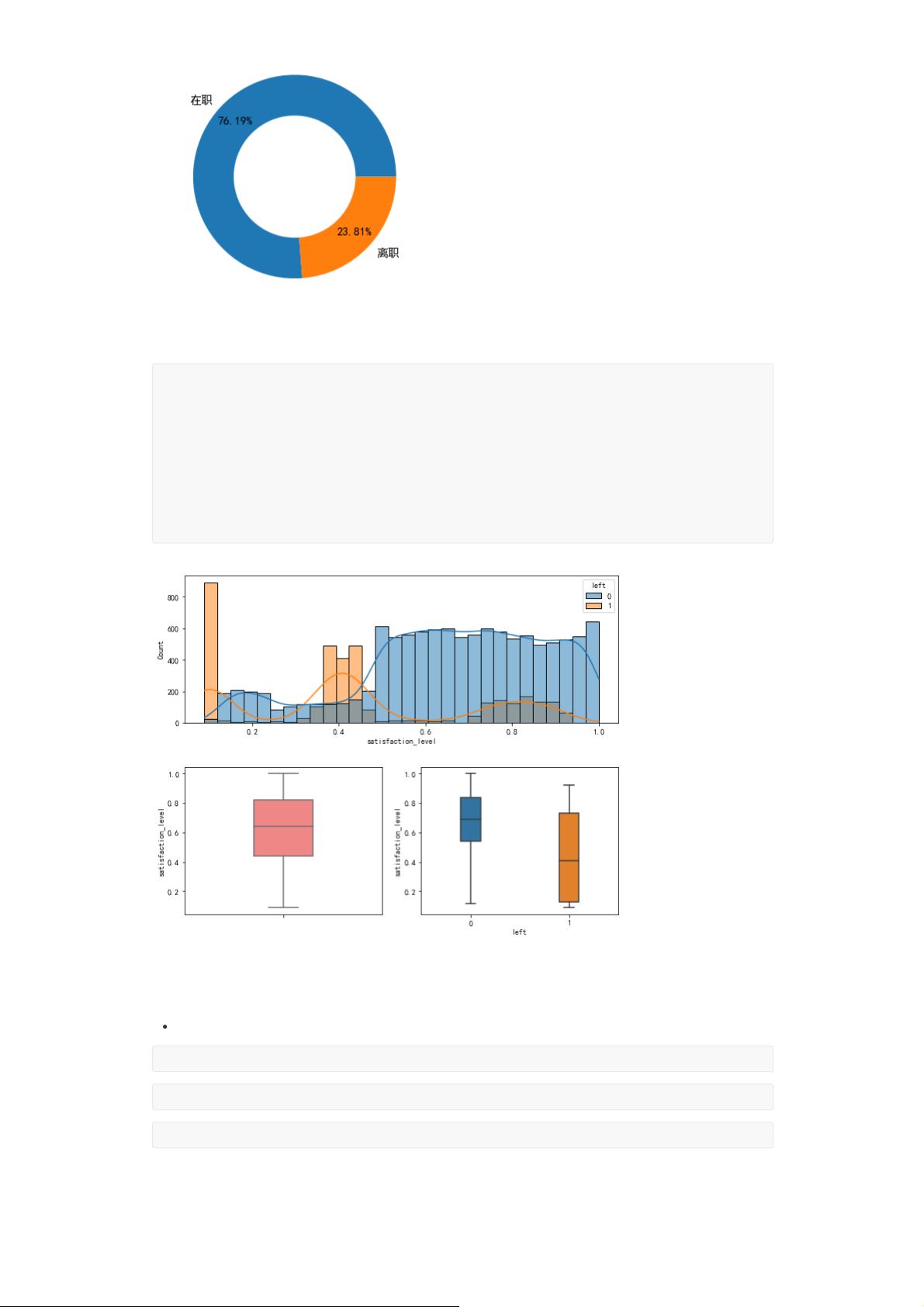
3.1 标签探索:员工离职状况概览
3.2 特征探索:员工对公司满意度与是否离职的关系
3.3 特征探索:最新考核评估与是否离职的关系
3.4 特征探索:参加项目数与是否离职的关系
3.5 特征探索:平均每月工作时长与是否离职的关系
3.6 特征探索:工作年限与是否离职的关系
3.7 特征探索:是否发生工作事故与是否离职的关系
3.8 特征探索:五年内是否晋升与是否离职的关系
3.9 特征探索:岗位与是否离职的关系
3.10 特征探索:薪资水平与是否离职的关系
4 特征工程&建立模型
4.1 编码:将文本型变量变为数值型
4.2 提取特征和标签并切分数据集
4.3 初步建模:建立benchmark
4.4 测试数据归一化对模型结果的影响
5 模型调优
1 数据概览
# 导入相应模块和包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Simhei']
plt.rcParams['axes.unicode_minus'] = False
# 导入原始数据
data = pd.read_csv("data/HR_comma_sep.csv")
data.head()
data.shape
(14999, 10)
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 satisfaction_level 14999 non-null float64
1 last_evaluation 14999 non-null float64
2 number_project 14999 non-null int64
3 average_montly_hours 14999 non-null int64
4 time_spend_company 14999 non-null int64
5 Work_accident 14999 non-null int64
6 left 14999 non-null int64