




一、前言
Kademlia协议(以下简称Kad)是美国纽约大学的PetarP. Maymounkov和David Mazieres.
在2002年发布的一项研究结果《Kademlia: A peerto -peer information system based on
the XOR metric》。
简单的说,Kad 是一种分布式哈希表(DHT)技术,不过和其他 DHT 实现技术比较,如
Chord、CAN、Pastry 等,Kad 通过独特的以异或算法(XOR)为距离度量基础,建立了一种
全新的 DHT 拓扑结构,相比于其他算法,大大提高了路由查询速度。
在 2005 年 5 月著名的 BiTtorrent 在 4.1.0 版实现基于 Kademlia 协议的 DHT 技术后,
很快国内的 BitComet 和 BitSpirit 也实现了和 BitTorrent 兼容的 DHT 技术,实现
trackerless 下载方式。
另外,emule 中也很早就实现了基于 Kademlia 类似的技术(BT 中叫 DHT,emule 中也叫
Kad,注意和本文简称的 Kad 区别),和 BT 软件使用的 Kad 技术的区别在于 key、value 和
node ID 的计算方法不同。
二、节点状态
在 Kad 网络中,所有节点都被当作一颗二叉树的叶子,并且每一个节点的位置都由其 ID
值的最短前缀唯一的确定。
对于任意一个节点,都可以把这颗二叉树分解为一系列连续的,不包含自己的子树。最
高层的子树,由 整颗树不包含自己的树的另一半组成;下一层子树由剩下部分不包含自己的
一半组成;依此类推,直到分割完整颗树。图 1 就展示了节点 0011 如何进行子树的划分:
图 1:节点 0011 的子树划分
虚线包含的部分就是各子树,由上到下各层的前缀分别为 0,01,000,0010。
Kad 协议确保每个节点知道其各子树的至少一个节点,只要这些子树非空。在这个前提
下,每个节点都可以通过 ID 值来找到任何一个节点。这个路由的过程是通过所谓的 XOR(异
或)距离得到的。
图 2 就演示了节点 0011 如何通过连续查询来找到节点 1110 的。节点 0011 通过在逐步
底层的子树间不断学习并查询最佳节点,获得了越来越接近的节点,最终收敛到目标节点上。
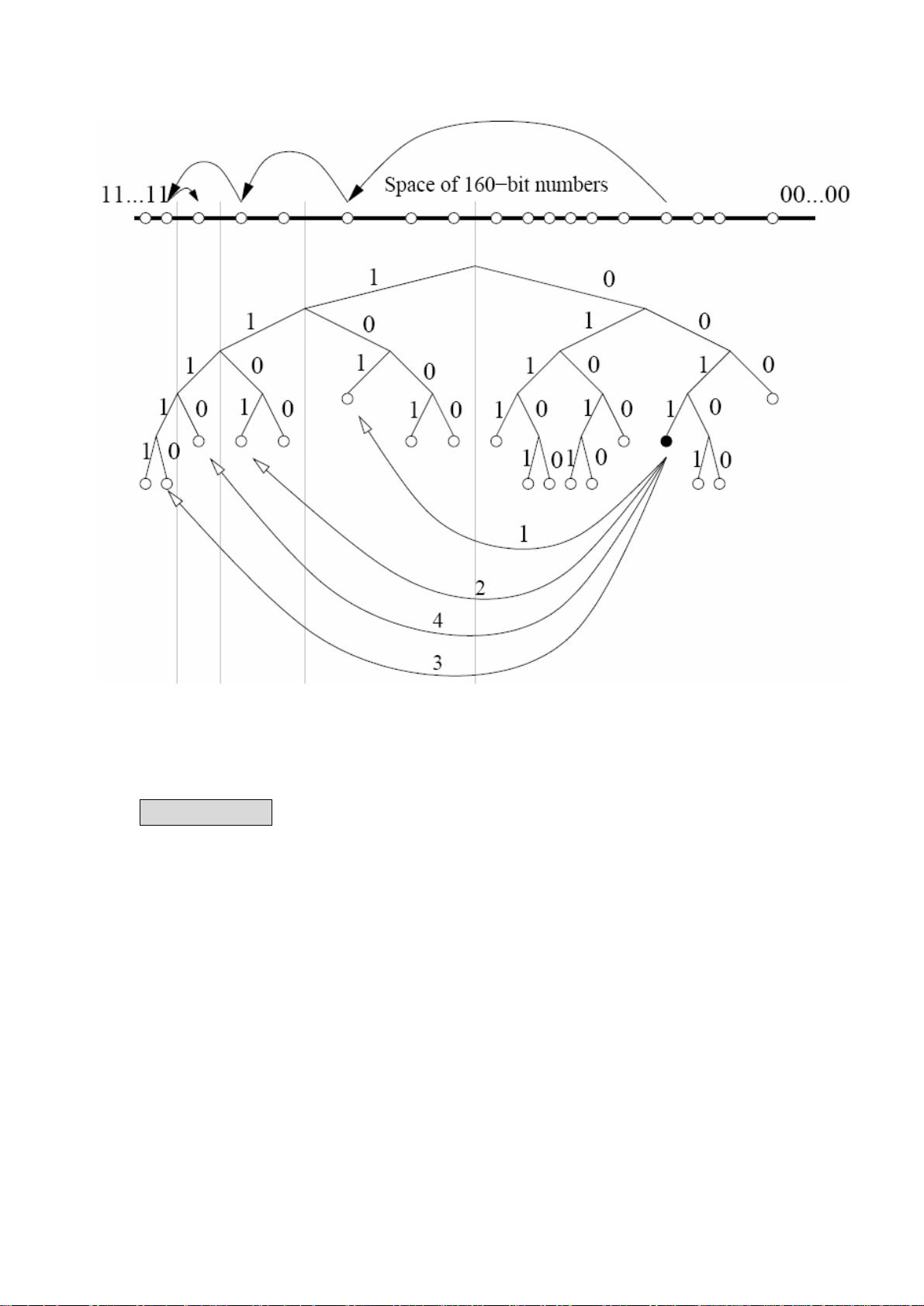
图 2:通过 ID 值定位目标节点
需要说明的是,只有第一步查询的节点 101,是节点 0011 已经知道的,后面 各 步 查询的
节点,都是由上一步查询返回的更接近目标的节点,这是一个递归操作的过程。
三、节点间距离
Kad 网络中每个节点都有一个 160bit 的 ID 值作为标志符,Key也是一个 160bit 的标志
符,每一个加入 Kad 网络的计算机都会在 160bit 的 key 空间被分配一个节点 ID(node ID)
值(可以认为 ID 是随机产生的), <key,value>对的数据就存放在 ID 值“最”接近 key 值的
节点上。
判断两个节点 x,y 的距离远近是基于数学上的异或的二进制运算,d(x,y) = x⊕y,既
对应位相同时结果为 0,不同时结果为 1。例如:
0
10
1
01
XOR
1
10
0
01
-------------
1
00
1
00
则这两个节点的距离为 32+4=36。
显然,高位上数值的差异对结果的影响更大。
对于异或操作,有如下一些数学性质:
l d(x, x) = 0

l d(x, y) > 0, if x ≠ y
l ∨x, y : d(x, y) = d(y, x)
l d(x, y) + d(y, z) ≧ d(x, z)
l d(x, y) ⊕ d(y, z) = d(x, z)
l ∨a≧ 0, b≧ 0, a + b≧ a ⊕ b
正如 Chord 的顺时针旋转的度量一样,异或操作也是单向性的。对于任意给定的节点 x
和距离⊿≧0,总会存在一个精确的节点 y,使得 d(x,y)= ⊿。另外,单向性也确保了对于
同一个 key 值的所有查询都会逐步收敛到同一个路径上,而不管查询的起始节点位置如何。
这样,只要沿着查询路径上的节点都缓存这个<key,value>对,就可以减轻存放热门 key 值
节点的压力,同时也能够加快查询响应速度。
四、K 桶
Kad 的路由表是通过一些称之为 K 桶的表格构造起来的。这有点类似 Tapestry 技术,其
路由表也是通过类似的方法构造的。
对每一个 0≦i≦160,每个节点都保存有一些和自己距离范围在区间
1
[2,2)
ii
+
内的一些
节点信息,这些信息由一些(IP address,UDP port,Node ID)数据列表构成(Kad 网络是靠
UDP 协议交换信息的)。 每 一 个这样的列表都称之为一个 K 桶,并且每个 K 桶内部信息存放
位置是根据上次看到的时间顺序排列,最近(least-recently)看到的放在头部,最后
(most-recently)看到的放在尾部。每个桶都有不超过 k 个的数据项。
一个节点的全部 K 桶列表如表 1 所示:
I 距离 邻居
0
01
[2,2)
0-1
0-k
(IP address,UDP port,Node ID)
......
(IP address,UDP port,Node ID)
1
12
[2,2)
1-1
1-k
(IP address,UDP port,Node ID)
......
(IP address,UDP port,Node ID)
2
23
[2,2)
2-1
2-k
(IP address,UDP port,Node ID)
......
(IP address,UDP port,Node ID)
……
i
1
[2,2)
ii
+
i-1
i-k
(IP address,UDP port,Node ID)
......
(IP address,UDP port,Node ID)
……














