基于STM32的孤立词语音识别
这是我毕业设计的论文,当年花了几个月来做,最终算是做出来个基本的功能样机。本来最开始
时想做一个图像识别进而实现体感操控,后来考虑到当年用的比较顺手的MCU中功能最强的就是
STM32,处理速度和内存容量都难以实现图像识别。于是就换成语音识别,图像识别留作以后再来
吧。
OK,废话不多说,上论文:
摘要:语音识别是机器通过识别和理解过程把人类的语音信号转变为相应文本或命令的技术,其
根本目的是研究出一种具有听觉功能的机器。本设计研究孤立词语音识别系统及其在STM32嵌入式平
台上的实现。识别流程是:预滤波、ADC、分帧、端点检测、预加重、加窗、特征提取、特征匹配。
端点检测(VAD)采用短时幅度和短时过零率相结合。检测出有效语音后,根据人耳听觉感知特性,计算
每帧语音的Mel频率倒谱系数(MFCC)。然后采用动态时间弯折(DTW)算法与特征模板相匹配,最终输出
识别结果。先用Matlab对上述算法进行仿真,经多次试验得出算法中所需各系数的最优值。然后将算
法移植到STM32嵌入式平台,移植过程中根据嵌入式平台存储空间相对较小、计算能力也相对较弱的
实际情况,对算法进行优化。最终设计并制作出基于STM32的孤立词语音识别系统。
关键词:STM32 孤立词语音识别 VAD MFCC DTW
目录
引 言
第一章 方案论证及选择
1.1系统设计任务要求
1.2硬件选择
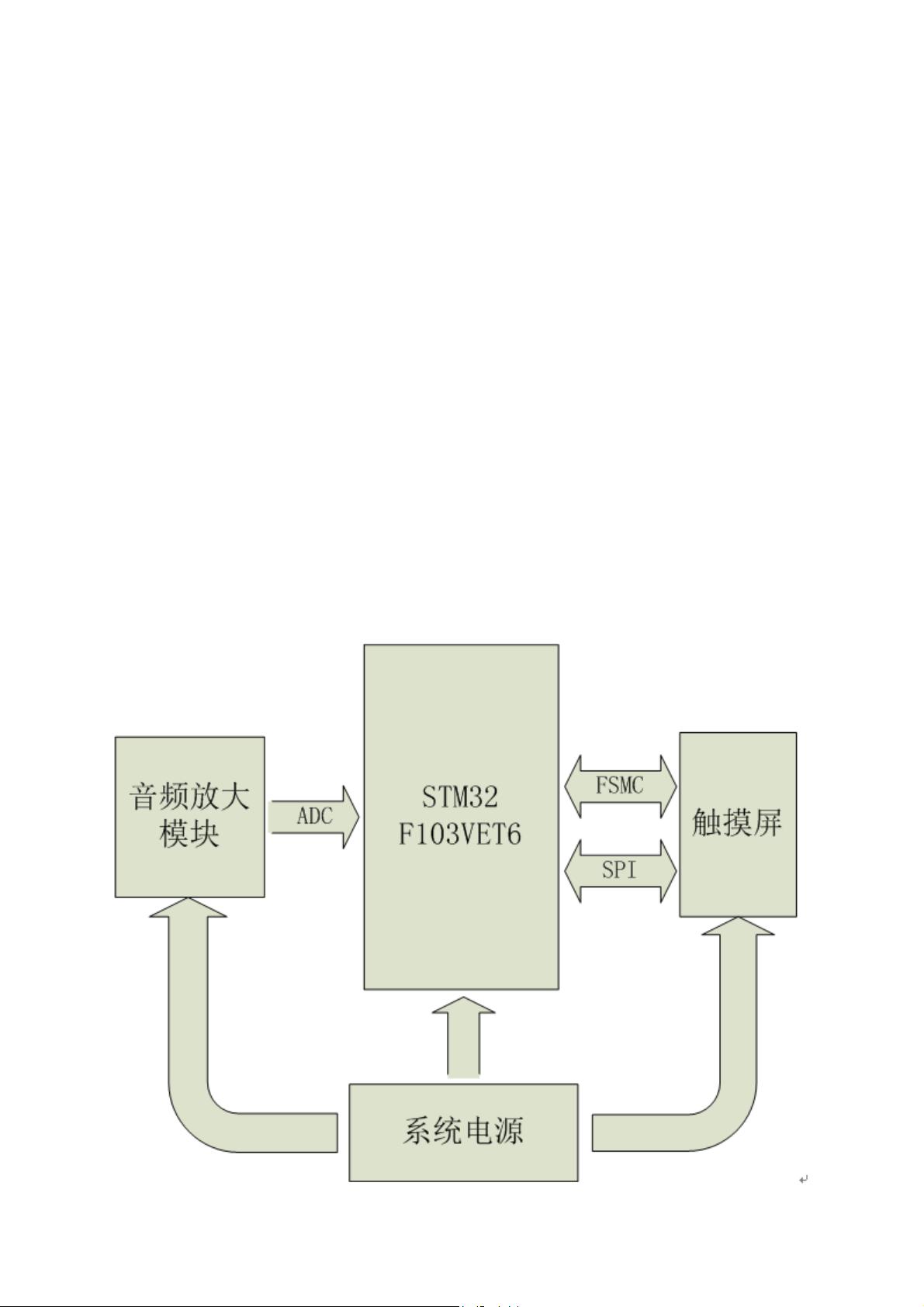
1.2.1 硬件方案总体介绍
1.2.2 MCU选择
1.2.3音频信号采集方案选择
1.2.4显示及操作界面选择
1.3算法选择
1.3.1软件算法总体介绍
1.3.2预处理算法选择
1.3.3端点检测算法选择
1.3.4特征提取算法选择
1.3.5特征匹配算法选择
第二章 系统设计