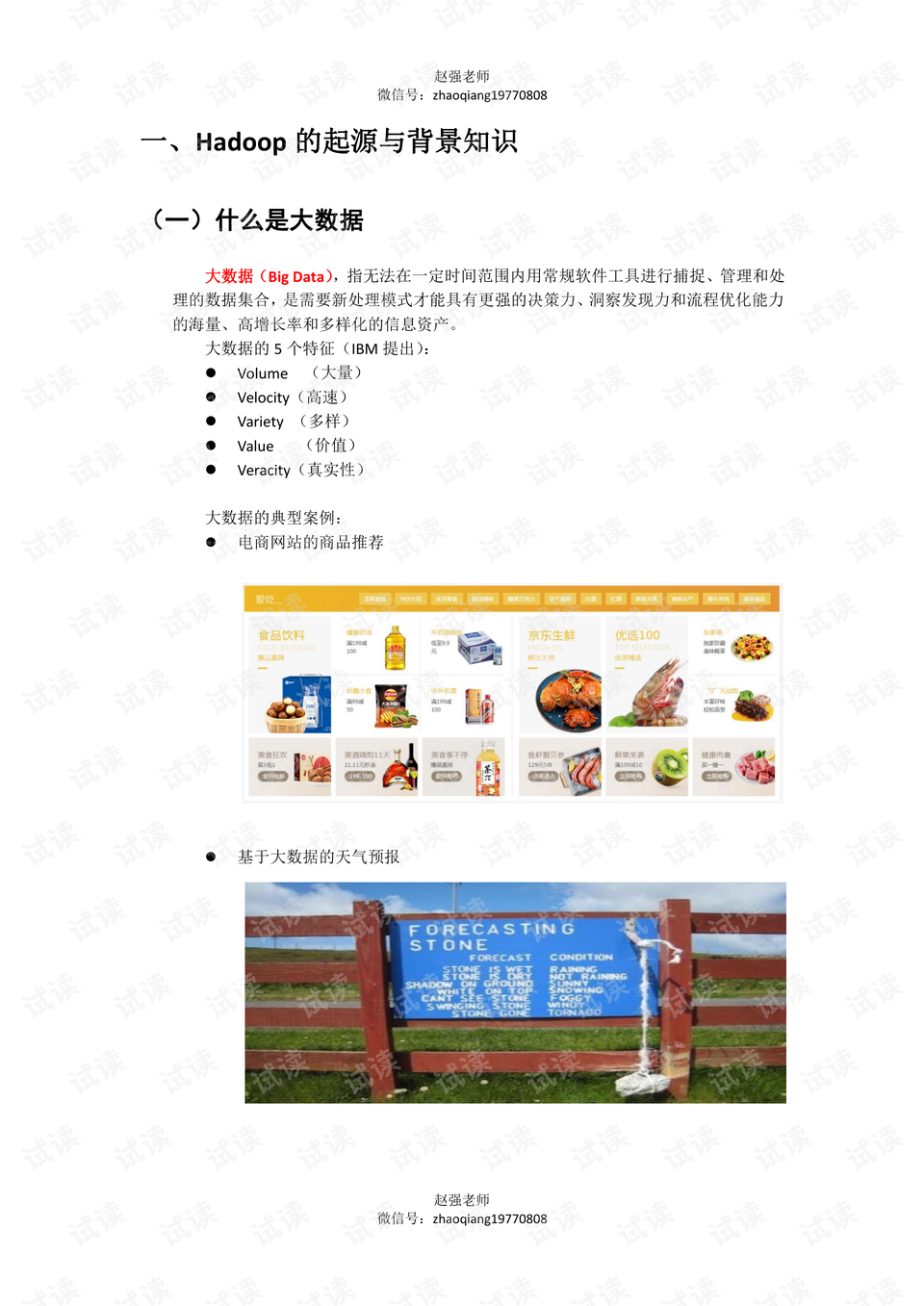
大数据基础与Hadoop的知识点涵盖了从大数据概念的定义到Hadoop技术框架及其生态系统组件的详细解读。在介绍过程中,首先从概念上阐述了大数据的本质及其五个显著特征:大量(Volume)、高速(Velocity)、多样(Variety)、价值(Value)和真实性(Veracity)。这些特征为大数据应用的特定需求提供了理论基础。
接着,文中深入解释了OLTP(联机事务处理过程)与OLAP(联机分析处理过程)的区别和联系。OLTP主要是处理即时交易,侧重于事务性数据的处理,通常应用于关系型数据库中,例如银行的日常交易处理。而OLAP则专注于数据仓库系统的数据分析处理,支持复杂的数据分析操作,如电商网站的商品推荐系统,更多地用于决策支持。
随后,大数据的另一个重要概念——数据仓库(Data Warehouse)被引入。数据仓库作为一个集中式的存储系统,为企业决策提供全面的数据支持,强调的是历史数据的汇总和分析,用于生成综合报告。
文中进一步阐述了Hadoop的起源和背景知识。Google作为大数据技术的先锋,其技术理念和架构设计对Hadoop的诞生有深远的影响。Hadoop的诞生可以追溯到Google公开的三篇核心论文,分别介绍了GFS(Google File System)、MapReduce算法和BigTable。这三篇论文揭示了Google处理海量数据的技术机制,对Hadoop的发展起到了关键作用。
Hadoop的生态体系中,HBase作为核心组件之一,是一个面向列的NoSQL数据库,建立在Hadoop的HDFS之上,可以处理海量的数据。除了HBase,文中还列举了其他一些常见的NoSQL数据库,如Redis、MongoDB和Cassandra,并简单介绍了它们的特点。
Hadoop的发展历史同样被提及。它起源于Lucene,一个搜索引擎库,之后发展成为Nutch项目的一部分。Google公开了其核心技术后,Nutch的性能得到了显著提升,进而吸引了Yahoo的关注,并最终由Yahoo招安了项目负责人Doug Cutting及其相关项目。在2005年秋天,Hadoop作为Lucene子项目Nutch的一部分正式引入Apache基金会,并在2006年3月发布了MapReduce和Nutch分布式文件系统(NDFS)。
Hadoop的诞生标志着大数据处理技术的一个重要转折点。它解决了传统技术在处理大数据时面临的性能瓶颈问题,借助于廉价的硬件和分布式计算模型,将大数据处理的经济性和可行性推向了新的高度。随着技术的不断演进,Hadoop逐步形成了一个包括HDFS、MapReduce、YARN和HBase在内的完整生态系统。
通过以上知识点的介绍,读者可以对大数据和Hadoop有一个全面的认识,理解到Hadoop在大数据处理领域的重要地位和作用,以及它如何通过借鉴Google的技术,为处理海量、多样化数据提供了一套行之有效的解决方案。此外,文中还揭示了Hadoop背后的一些创新思想,如使用普通PC服务器代替昂贵的超级计算机,以及如何利用全球分布的数据中心和互联网经济模式进行成本优化。这些内容不仅为初学者提供了基础知识框架,也为专业人士提供了深入理解Hadoop的机会。