【Python爬取微博数据生成词云图片】
在Python编程中,生成词云图片是一种常见的数据可视化方式,尤其适用于展示文本中的高频词汇。本教程将教你如何利用Python爬取微博数据并生成词云图片,这对于数据分析、情感分析或个性化礼物制作等场景都非常有用。
**一、前言**
词云图(Word Cloud)能够直观地展示大量文本中各个词汇出现的频率,通过大小和颜色的差异来突出重点。结合Python的爬虫技术,我们可以获取微博上的公开数据,然后利用词云库生成个性化的词云图片。
**二、准备工作**
在开始之前,确保你的环境已经安装了以下Python库:
- jieba:用于中文分词
- matplotlib:绘图库
- numpy:数值计算库
- pyparsing:解析表达式库
- requests:用于HTTP请求
- scipy:科学计算库
- wordcloud:生成词云的库
你可以通过`pip`一次性安装这些依赖,或者使用`Anaconda`环境管理器。
```bash
pip install -r requirement.txt
```
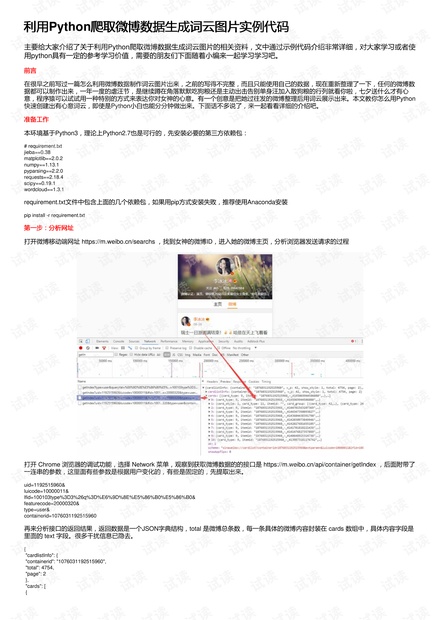
**三、分析网址**
1. 访问微博移动端搜索页面:https://m.weibo.cn/searchs
2. 找到目标用户,进入其个人主页。
3. 使用Chrome浏览器的开发者工具查看网络请求,找到获取微博数据的API接口:https://m.weibo.cn/api/container/getIndex
4. 注意接口参数,如`uid`(用户ID)、`luicode`、`lfid`等,其中`uid`和`containerid`与特定用户相关,`page`用于分页。
**四、构建请求头和查询参数**
- 构造请求头,模仿浏览器发送请求,确保包含`Host`、`Referer`和`User-Agent`等信息。
- 定义查询参数,包括`uid`、`luicode`、`featurecode`、`type`、`value`、`containerid`和`page`。
**五、编写爬虫**
1. 使用`requests`库发起HTTP GET请求,将上述请求头和参数拼接到URL中。
2. 解析返回的JSON数据,获取`total`(总微博数)和`cards`(微博内容数组)。
3. 循环遍历`cards`,提取每条微博的`text`字段,存储所有微博文本。
**六、处理文本数据**
1. 使用`jieba`进行中文分词,去除停用词(如“的”、“是”、“在”等)。
2. 对分词后的词汇进行频率统计。
**七、生成词云图片**
1. 使用`wordcloud`库创建词云对象,设置背景色、字体大小、形状等参数。
2. 将统计好的词频数据传入词云对象,生成词云图片。
3. 使用`matplotlib`展示或保存词云图片。
通过以上步骤,你可以为任何微博用户生成词云图片,无论是用于个人项目还是表达创意,都是一个有趣且实用的技能。记得在爬取数据时遵守网站的robots.txt规则,尊重他人的隐私,合法合规地使用数据。