
# Temporal-Difference Learning Demos in MATLAB
In this package you will find MATLAB codes which demonstrate some selected examples of *temporal-difference learning* methods in *prediction problems* and in *reinforcement learning*.
To begin:
* Run `DemoGUI.m`
* Start with the set of predefined demos: select one and press *Go*
* Modify demos: select one of the predefined demos, and modify the options
Feel free to distribute or use package especially for educational purposes. I personally, learned too much from cliff-walking.
The repository for the package is hosted on [GitHub](https://github.com/sinairv/Temporal-Difference-Learning).
## Why temporal difference learning is important
A quotation from *R. S. Sutton*, and *A. G. Barto* from their book *Introduction to Reinforcement Learning* ([here](http://www.cs.ualberta.ca/~sutton/book/ebook/node60.html)):
> If one had to identify one idea as central and novel to reinforcement learning, it would undoubtedly be temporal-difference (TD) learning.
Many basic reinforcement learning algorithms such as *Q-Laerning* and *SARSA* are in essence *temporal difference learning methods*.
## Demos
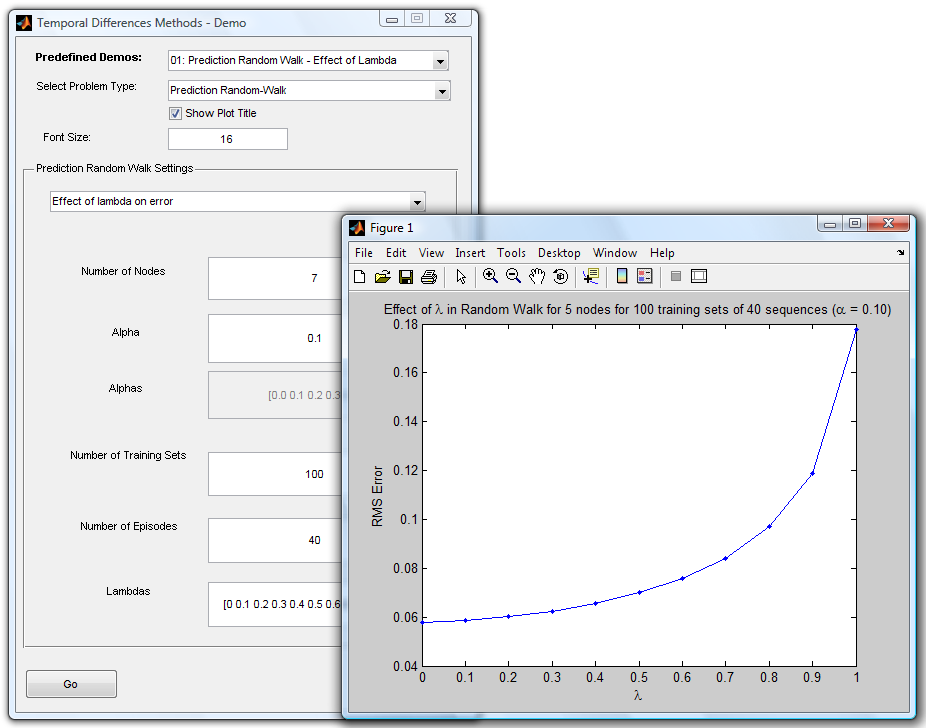
* *Prediciton random walk*: see how precise we can predict the probability of visiting nodes
* *RL random walk*: see how RL generated random walk policy converges the computed probabilities.
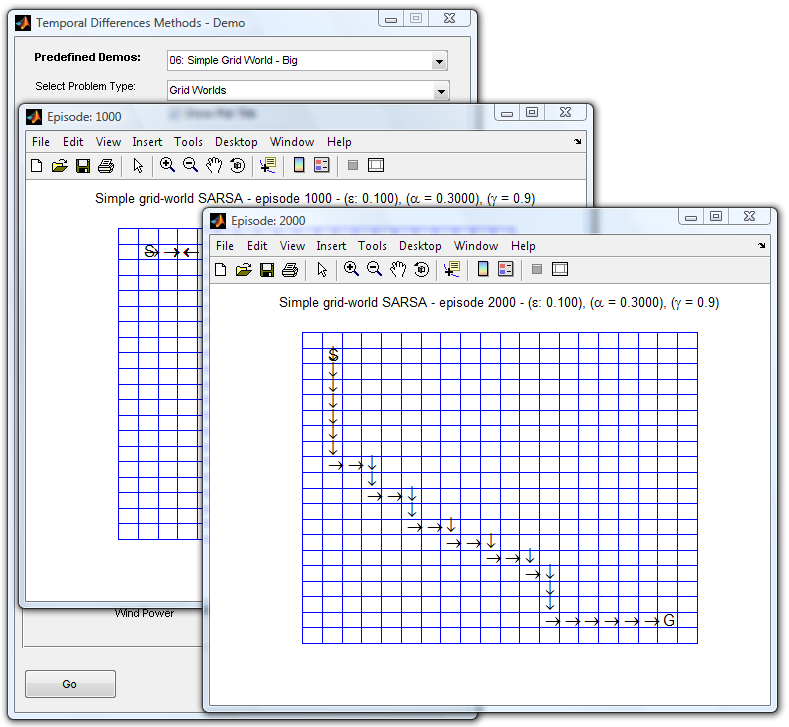
* *Simple grid world (with and without king moves)*: see how RL generated policy helps the agent find the goal through time (by *king-moves* it is meant moving along the four main directions and the diagonals, i.e., the way king moves in chess).
* *Windy grid world*: the wind distracts the agent from its destination sought by its actions. See how RL solves this problem.
* *Cliff walking*: the agent should reach its destination while avoiding the cliffs. A truly instructive example, which shows the differences between *on-policy*, and *off-policy* learning algorithms.
## References
[1] Sutton, R. S., "Learning to predict by the methods of temporal differences, In *Machine Learning*, pp. 9-44, 1988 (available [online](http://webdocs.cs.ualberta.ca/~sutton/papers/sutton-88.pdf))
[2] Sutton, R. S. and Barto, A. G., "Reinforcement learning: An introduction," 1998 (available [online](http://webdocs.cs.ualberta.ca/~sutton/book/ebook/the-book.html))
[3] Kaelbling, L. P., Littman, M. L., and Moore, A. W., "Reinforcement learning: A survey," *Journal of Artificial Intelligence Research*, Vol.4, pp.237-285, 1997 (available [online](http://www.jair.org/media/301/live-301-1562-jair.pdf))
## Contact
Copyright (c) 2011 Sina Iravanian - licensed under MIT.
Homepage: [sinairv.github.io](https://sinairv.github.io)
GitHub: [github.com/sinairv](https://github.com/sinairv)
Twitter: [@sinairv](http://www.twitter.com/sinairv)
## Screenshots
Prediction random walk demo:
RL random walk demo:

Simple grid-world demo:
 Temporal-Difference-Learning-master.zip (21个子文件)
Temporal-Difference-Learning-master.zip (21个子文件)  Temporal-Difference-Learning-master
Temporal-Difference-Learning-master  ReadMe.md 3KB src DemoGUI.m 40KB GridWorldSARSA.m 5KB DemoGUI.fig 9KB WindyGridWorldQLearning.m 5KB FindColBaseCenter.m 535B DrawActionOnCell.m 1KB CliffWalkingQLearning.m 5KB DrawTextOnCell.m 493B WindyGridWorldSARSA.m 5KB GenerateRandomWalkSequence.m 888B PredictionRandomWalk.m 3KB DrawWindyEpisodeState.m 798B DrawEpisodeState.m 614B DrawCliffEpisodeState.m 721B PredictionRandomWalkAlphaEffect.m 2KB RLRandomWalk.m 2KB FindCellCenter.m 445B GridWorldQLearning.m 5KB CliffWalkingSARSA.m 5KB DrawGrid.m 937B
ReadMe.md 3KB src DemoGUI.m 40KB GridWorldSARSA.m 5KB DemoGUI.fig 9KB WindyGridWorldQLearning.m 5KB FindColBaseCenter.m 535B DrawActionOnCell.m 1KB CliffWalkingQLearning.m 5KB DrawTextOnCell.m 493B WindyGridWorldSARSA.m 5KB GenerateRandomWalkSequence.m 888B PredictionRandomWalk.m 3KB DrawWindyEpisodeState.m 798B DrawEpisodeState.m 614B DrawCliffEpisodeState.m 721B PredictionRandomWalkAlphaEffect.m 2KB RLRandomWalk.m 2KB FindCellCenter.m 445B GridWorldQLearning.m 5KB CliffWalkingSARSA.m 5KB DrawGrid.m 937B
weixin_38685961
- 粉丝: 8
- 资源: 907









最新资源
- 发那科系统整套梯形图设计 FANUC全套PMC设计 发那科标 准PLC 完美解决方案 ##带中文解释## 内容很全 请仔细看完: 1.刀库程序设计(斗笠 圆盘 夹臂 机械手 伞型 都包
- stm32 gd32爱玛电动车控制器资料 电动车控制器原理图、PCB和程序 大厂成熟电机foc控制 送eg89m52的原理图和pcb
- 基于Go语言的现代化开源K8s面板——1Panel官方出品KubePi设计源码
- 基于JavaScript的Sewise Player网页HTML5视频播放器设计源码
- 小神农V7(修复眼镜).zip
- 基于Vue框架的银行科技岗AI云账户系统前端设计源码
- Screenshot_2025-01-15-00-13-41-471_com.tencent.mtt.jpg
- Screenshot_2025-01-15-00-08-47-906_com.tencent.mobileqq.jpg
- 250467c518b0a66217a647d11a6a9c831736870765675.jpg
- 基于Tcl语言的GNU TeXmacs插件集合设计源码
- Screenshot_2025-01-15-00-04-33-283_com.kuaishou.nebula.jpg
- 基于Vue框架的easy-send局域网文本文件共享小工具设计源码
- 基于JavaScript和微信小程序技术的钓场信息预约与管理小程序设计源码
- PSO-RBF和RBF粒子群优化径向基神经网络多输入多输出预测(Matlab完整源码和数据)
- 三菱fx3u+485ADP-MB与3台台达变频器modbus通讯程序 功能:通过三菱fx3u 485ADP-MB板对3台台达变频器进行modbus通讯,实现频率设定,启停控制,输出频率读取,输出电压读
- 除尘程序 写的FB块了,可以直接调用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0