
一、 实验目的与要求
1.1 实验目的:
掌握 Hbase shell 操作。
1.2 实验要求:
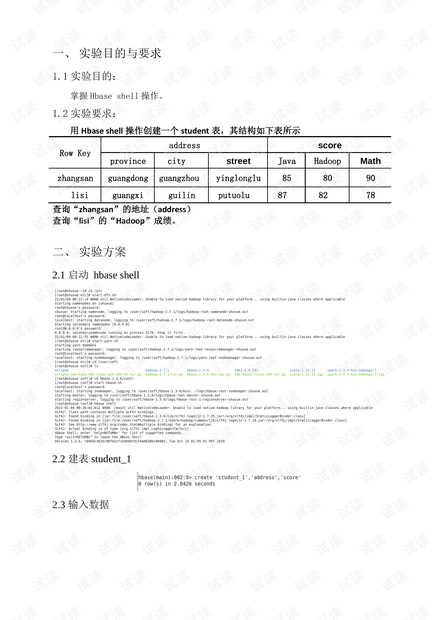
用 Hbase shell 操作创建一个 student 表,其结构如下表所示
Row Key
address
score
province
city
street
Java
Hadoop
Math
zhangsan
guangdong
guangzhou
yinglonglu
85
80
90
lisi
guangxi
guilin
putuolu
87
82
78
查询“zhangsan”的地址(address)
查询“lisi”的“Hadoop”成绩。
二、 实验方案
2.1 启动 hbase shell
2.2 建表 student_1
2.3 输入数据

冷漠的打工人
- 粉丝: 2
- 资源: 8









最新资源
- ssm在线购书商城系统+vue.zip
- ssm在线云音乐系统的设计与实现+jsp.zip
- ssm园区停车管理系统+jsp.zip
- ssm影视企业全渠道会员管理系统的设计与实现+vue.zip
- ssm游戏攻略网站的设计与实现+vue.zip
- ssm医院住院综合服务管理系统设计与开发+vue.zip
- ssm亿互游在线平台设计与开发+vue.zip
- 三菱FX3U源码,三菱PLSR源码 总体功能和指令可能支持在RUN中下载程序,支持注释的写入和读取,有脉冲输出与定位指令(包括PLSY PWM PLSR PLSV DRVI DRVA 等指令)的代
- ssm应急资源管理系统+jsp.zip
- ssm医院门诊挂号系统+jsp.zip
- ssm医院住院管理系统+vue.zip
- ssm医用物理学实验考核系统+jsp.zip
- ssm学院学生论坛的设计与实现+vue.zip
- ssm医学生在线学习交流平台+vue.zip
- ssm亚盛汽车配件销售业绩管理统+jsp.zip
- 研控步进电机驱动器方案 验证可用,可以生产,欢迎咨询实际价格,快速掌握核心技术 包括硬件原理图 PCB源代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论20