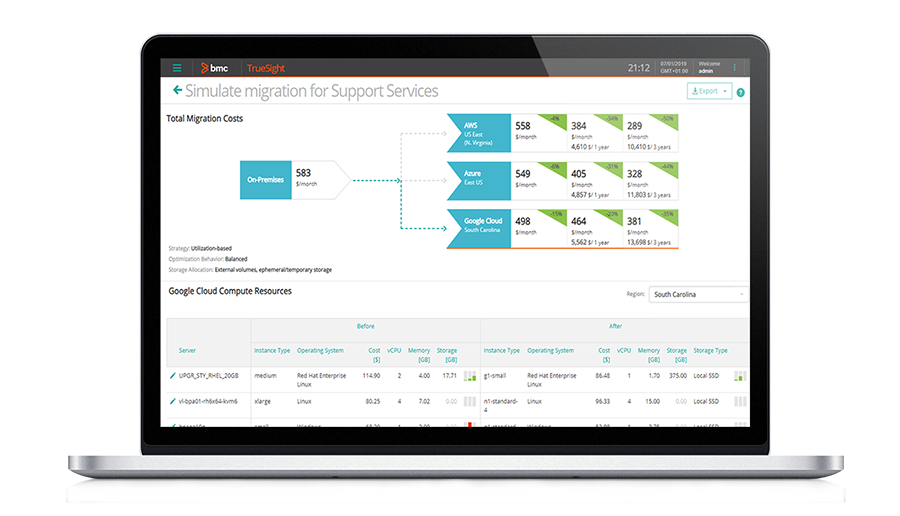
Réduire le temps moyen de récupération (MTTR) avec une analyse des événements de premier ordre et l’automatisation sur l’ensemble de votre infrastructure – centres de données et environnements cloud
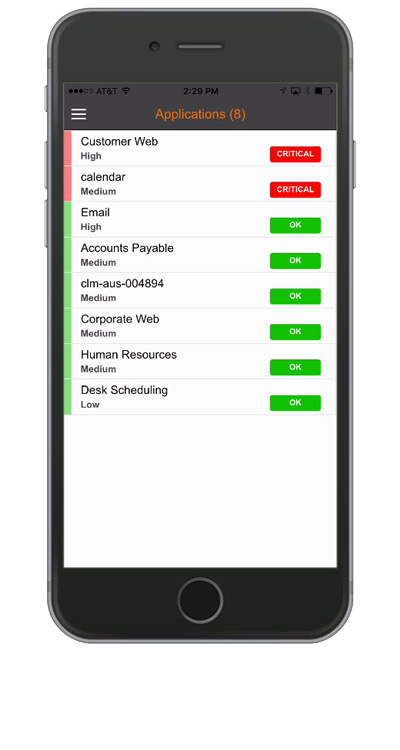
- Apprendre sans cesse des comportements normaux et anormaux de l’infrastructure et des services d’application
- Réduire le bruit des événements à l’aide d’analyses brevetées des événements, des mesures des performances et des journaux
- Simplifier les opérations avec un gestionnaire de gestionnaires en intégrant tous les événements et journaux, et en surveillant les données
- Générer automatiquement des tickets d’incident et informer le centre de services avant que les utilisateurs ne soient affectés
- Identifier et noter les causes probables et corriger les problèmes de performance dans un flux de travail simple
- Passer rapidement du niveau de service métier au niveau des composants d’application
- Comprendre l’expérience utilisateur en test et en production à l’aide d’une surveillance synthétique des utilisateurs